LPCNet模型理解
人发声音是通过人肺部挤压出来的气流通过声带产生震动波,通过空气传播到我们的耳朵。物理学用声源激励(模拟从肺部发出气流)和声道响应系统可以构建传统声码器。
- 声源过滤器模型(Source–filter model)就是这种模型,它的声道模型就是LPC这种,激励是开关(清音 浊音还是其他无声之类的)。响应系统是过去时间段里面的声音的振幅变种的线性组合。
- 神经网络模型是把声源激励模型和声道响应用一组神经网络建模(计算量很大)。
- LPCNet是两者结合,用LPC做响应系统,用神经网络做声源激励模型(把残差信号当作激励源)(文中还提出了另一个好处就是补偿了u-law的量化噪声)。它计算量小,3GFLOPS,可能在智能机上架设,物理+神经网络保证了良好的预测。
理解:神经网络构建激励信号系统很好理解,此处重点理解物理模型的构建。也就是没有激励信号的每一时刻,他们的输出呈现怎样的关系又是如何建模。想象此刻在空旷的舞台上一位大佬正兴奋的演讲,讲到兴奋处突然麦停止工作了,但下一时刻我们耳朵仍然有余音传入。分析这一时刻,相当于给过激励后突然停止,此刻相当于整个系统的零输入响应,系统内有能量存余,求解此刻后的后波形问题就是解零输入响应微分方程。微分方程的解是基于时间戳的线性组合,和LPC物理建模的表达式相同:
模型结构
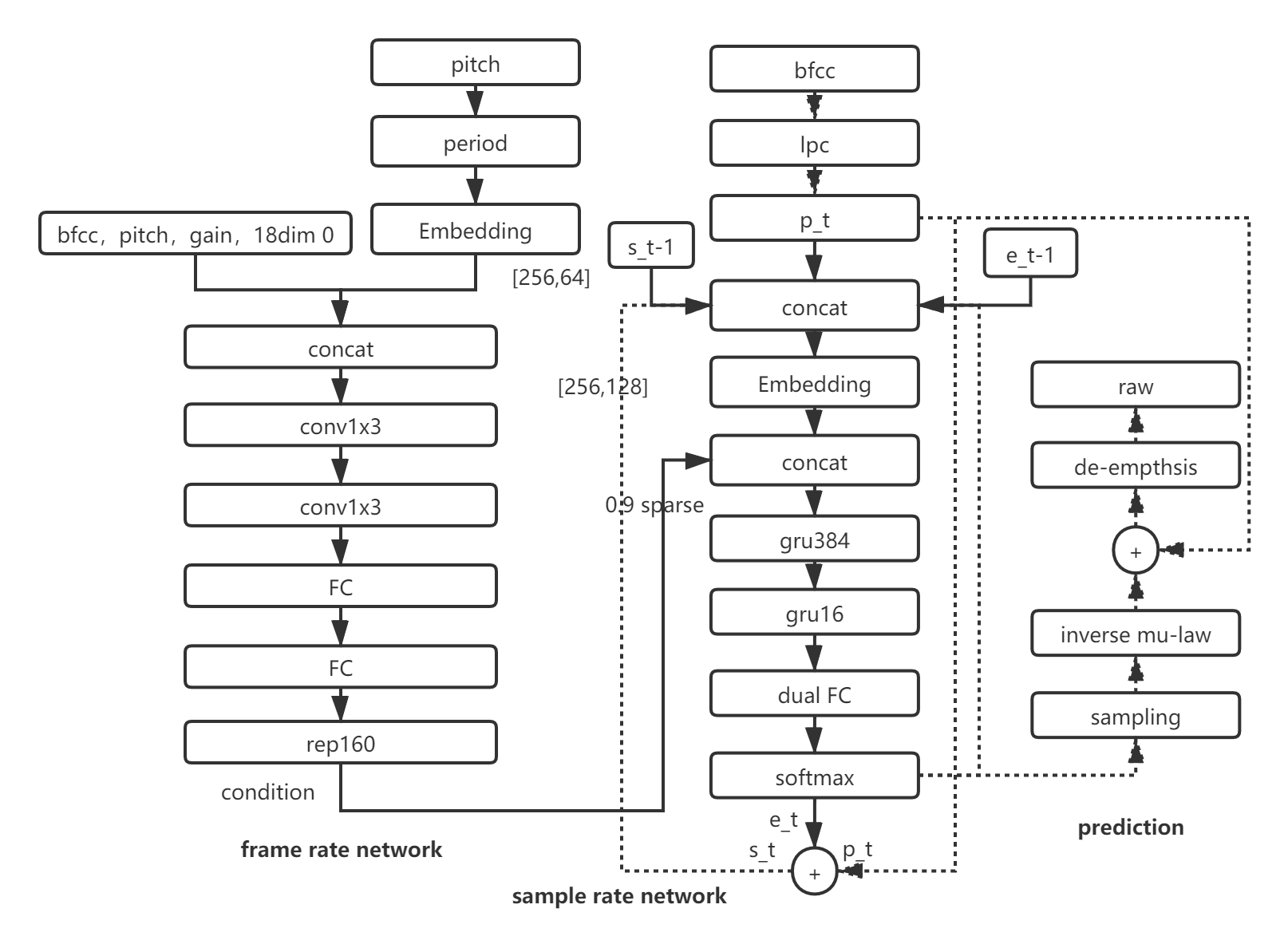
下图展示了LPCNet的模型结构。它由三个部分组成:帧级别网络,采样点级别网络和LPC线性预测模块。帧级别网络用于特征提取,采样点级别网络用于预测激励信号(残差),LPC预测模块根据前N个时刻的值的线性组合预测下一时刻的(注意这里的系数不是训练参数)。
线性预测
是一阶线性响应系统,认为每一时刻的幅值变种是上N个时刻(文中取16)的线性组合加上残差信号。残差信号作为激励源将决定下一个时刻声音幅值走向。s是前M(论文中取16)个采样点的振幅变种(变换过),$p_t$是预测系数。预测系数在进入神经网络前已经基于future计算好(Levinson-Durbin算法,看了一下是用迭代法降低复杂度到N平方),预测时s就是合成的振幅变种。
Frame rate network
该网络是帧级别,102维(64维pitch嵌入和55维特征中的38维,38维中[18:36]相关系数置零)特征穿过两个串联的两个卷积网络和全连接层用来提取该帧的语言特征。源码中和论文中不同,没有resnet。该128维特征作为条件向量进行160次广播,输入到sampe rate network。理解为我们SV中的embedding,它包含了整个帧的语音学特征。需要注意的是,在采样级别网络中的当前帧,该向量是保持不变的。
Sample rate network
该网络是采样点级别,输入时concat特征向量,上一时刻的激励信号,上一时刻的幅值变种预测,以及响应预测。首先进行标量到128维tensor的嵌入,然后经过两层GRU(第一层细胞多,训练时逐步把weight小的细胞置零减小运算量,第二层细胞少,具体量是384和64),然后进入Dual FC网络,按照元素相乘操作后得到两个128维,按元素相加。经过softmax预测激励的概率分布(概率分布经过后处理减少噪声影响)。LOSS是采样点真实值和预测值的差。
论文分析
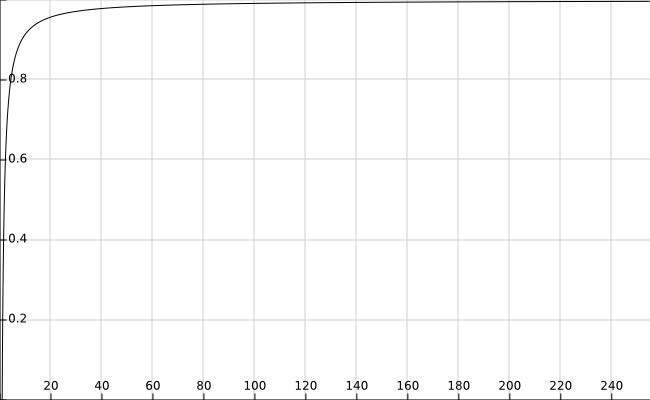
pre-emphsis
pre-emphsis滤波来提升高频能量,是个一阶高通滤波器。采用pre-enphsis的理由是$\mu$-law量化噪声在高频段更能明显听出来,因为高频量化后有所衰减,所以高频量化噪声大。因此通过pre-emphsis加大高频的能量,使量化后更均衡。最后还可以通过de-emphsiis去除。系数0.85决定了阈值,是试验出来的把。
下图横坐标是频率,纵坐标是映射比例。
$\mu$-law transfer
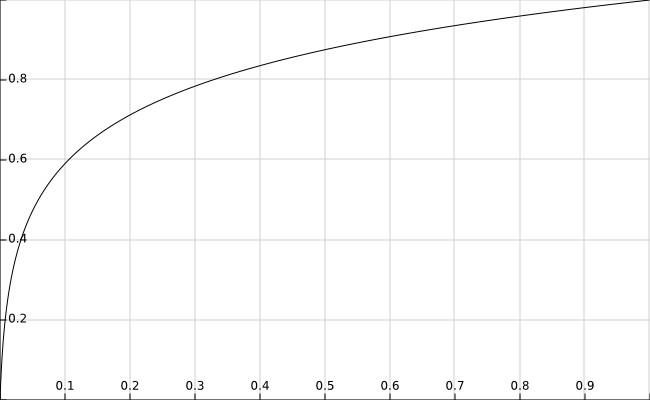
$\mu$-law同样只是一种刻度映射,类似mel刻度映射。下图是映射关系图。
加噪处理
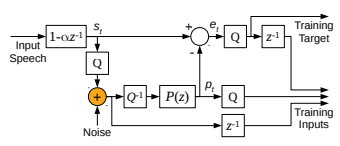
代码中在加入噪声的位置是激励之后,LPCNet把上一个sample的激励预测值作为输入进入下一个timestep,减少训练和预测的误差。并且噪声添加位置是在et之后。注意激励值的量化是在pcm和线性预测相减后进行的。
稀疏矩阵
论文中提到应用稀疏矩阵来减少运算,加快训练。对gruA的循环单元的weights进行稀疏化,分别是reset门,update门和候选隐藏单元的去权重$w_{hr},w_{hz},w_{hh}$。keras的回调函数在每个batch后(on_batch_end)调用sparsify。LPCNet的GRUA的稀疏化分为三个阶段:[batch 0,t_strat-1]:不稀疏化,正常训练。[t_start,t_end-1]:batch%interval=0稀疏化,源码中每隔400个batch进行稀疏化。[t_end,inf]:每个batch后稀疏化。把循环权重乘以一个对角线为1,其他位置根据阈值进行二值化的矩阵进行权值稀疏化,wr,wu的稀疏化阈值相等且高于wh,随着训练进行非零权重数量会变少。实际过程中稀疏化以1*16的向量进行分块处理,减小内存占用,并且作者表明在矩阵块大小为16时,结果较好。对角线位置的权重未进行改变。
嵌入矩阵
data的的组成分别是,128维的condition向量,和uint8的标量线性预测,上一采样点的signal和上一采样点的激励预测。为了进行归一化操作和tensor化,作者把uint的每一个每一个level对后三者进行嵌入,乘以嵌入矩阵E,得到128维tensor T。同时在pitch的tensor化也应用了嵌入矩阵,矩阵的shape是[256,64],经过嵌入的pitch和38维特征concat成102维作为输入训练帧级别网络。更巧妙的地方是通过tensor T以及f和接下来gruA中的非循环单元相乘并提前保存,大大减少了gru的运算量,该技术化处理和稀疏矩阵从根本上实现了对网络加速,才使实时性成为可能。在同一设备上,LPCNet的前向合成时间是实时的四分之一,而WaveNet大约是实时的二十五倍。 实现加速的细节:GRU中的循环单元W_hr,W_hz,W_hh的shape是(384,384),而非循环单元W_xr,W_xz,W_xh的shape是(512384),非循环单元的计算占据更多的计算量。而把128维的condition vector f 和非循环单元提前计算,用于采样点级别网络的160次循环,这是减少计算量的第一重;把1283维的嵌入矩阵(乘以三代表s_t,p_t+1,e_t)提前和非循环单元相乘,同样用于采样点级别网络的160次循环,这是减少计算量的第二重。
采样的概率分布处理
采样时为了降低噪声,根据音高相关系数来对概率分布给与权重。音高变化小的音高相关系数应该小,权重大。该采样处理,实现了噪声过滤。同时注意,该技术处理只在前向的py脚本中使用,训练过程中并未使用。