python多线程与GIL(Global Interpreter Lock)
python多进程多线程是个古老的话题了,最近翻到之前自己写的文档,顺手摘录到博客上了。
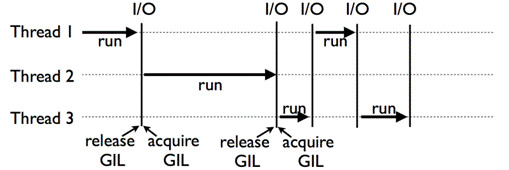
python的全局解释器锁使得任意时刻只有一个线程在真正运行,所以呢,可以讲它是”假多线程”。他能对脚本的提速仅仅体现在IO操作中,因为IO操作是可以和线程并行的,所以它节省了IO操作时间。正是由于它的GIL锁的出现,才会使得多线程的种种弊端。
multiprocessing.Process简要介绍
multiprocessing 是一个用与 threading 模块相似API的支持产生进程的包。 multiprocessing 包同时提供本地和远程并发,使用子进程代替线程,有效避免 Global Interpreter Lock 带来的影响。
class multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
group 应该始终是 None ;它仅用于兼容 threading.Thread 。 target 是由 run() 方法调用的可调用对象。它默认为 None ,意味着什么都没有被调用。 name 是进程名称(有关详细信息,请参阅 name )。 args 是目标调用的参数元组。 kwargs 是目标调用的关键字参数字典。如果提供,则键参数 daemon 将进程 daemon 标志设置为 True 或 False 。如果是 None (默认值),则该标志将从创建的进程继承。
类的方法:
start()启动进程活动。
join([timeout])如果可选参数 timeout 是 None (默认值),则该方法将阻塞,直到调用 join() 方法的进程终止。一个进程可以被 join 多次。进程无法join自身,因为这会导致死锁。
is_alive()返回进程是否还活着。
daemon守护进程的标志,一个布尔值。这必须在 start() 被调用之前设置。
close()关闭 Process 对象,释放与之关联的所有资源。
例子
通过创建一个 Process 对象然后调用它的 start() 方法来生成进程。 Process 和 threading.Thread API 相同。
from multiprocessing import Process
def f(name):
print('hello', name,'!')
if __name__ == '__main__':
p = Process(target=f, args=('zhuxiaoxu',))
p.start()
p.join()
运行结果:

Join
join的作用是阻塞主进程(主进程等待p进程执行完毕,才继续执行),和多线程一样。python 默认参数创建线程后,不管主线程是否执行完毕,都会等待子线程执行完毕才一起退出,有无join结果一样。join方法有一个参数是timeout,即如果主线程等待timeout,子线程还没有结束,则主线程强制结束子线程。
例子
from multiprocessing import Process
import time
def f(name):
time.sleep(10)
print('hello',name,'!')
if __name__ == '__main__':
p = Process(target = f,args = ('zhuxiaoxu',))
p.start()
p.join()
print('I M THE MAIN PROCESS!')
运行结果:

上下文和启动方法
要选择一个启动方法,应该在主模块的 if name == ‘main’ 子句中调用 set_start_method() 。
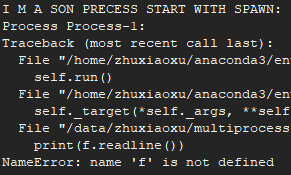
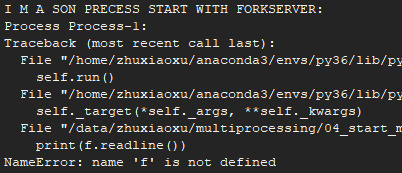
import multiprocessing as mp
def foo():
print('I M A SON PRECESS START WITH SPAWN:')
print(f.readline())
if __name__ == '__main__':
mp.set_start_method('spawn')
f = open('01_multiprocessing.py','r')
p = mp.Process(target=foo, args=())
p.start()
p.join()
spawn
父进程启动一个新的Python解释器进程。子进程只会继承那些运行进程对象的 run() 方法所需的资源。特别是父进程中非必须的文件描述符和句柄不会被继承。相对于使用 fork 或者 forkserver,使用这个方法启动进程相当慢。
fork
父进程使用 os.fork() 来产生 Python 解释器分叉。子进程在开始时实际上与父进程相同。父进程的所有资源都由子进程继承。请注意,安全分叉多线程进程是棘手的。linux中默认的启动方法,紫禁城继承了来自父进程的所有文件描述符。

forkserver
程序启动并选择 forkserver 启动方法时,将启动服务器进程。从那时起,每当需要一个新进程时,父进程就会连接到服务器并请求它分叉一个新进程。分叉服务器进程是单线程的,因此使用 os.fork() 是安全的。没有不必要的资源被继承。
扩展
Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(file descriptor)是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。程序刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。如果此时去打开一个新的文件,它的文件描述符会是3。
进程间通信
multiprocessing 支持进程之间的两种通信通道:队列和管道。
Queue
Queue 类是一个近似 queue.Queue 的克隆。 队列是线程和进程安全的。
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get())
p.join()
运行结果:

Pipe
Pipe() 函数返回一个由管道连接的连接对象,默认情况下是双向的。返回的两个连接对象 Pipe() 表示管道的两端。每个连接对象都有 send() 和 recv() 方法(相互之间的)。请注意,如果两个进程(或线程)同时尝试读取或写入管道的 同一 端,则管道中的数据可能会损坏。当然,同时使用管道的不同端的进程不存在损坏的风险。
from multiprocessing import Process, Pipe
def f(conn):
conn.send([1111, None, 'hello'])
conn.close()
if __name__ == '__main__':
a, b = Pipe()
p = Process(target=f, args=(a,))
p.start()
print(b.recv())
p.join()
运行结果:

进程之间的同步和Lock
python在操作数据的时候,比如两个加法指令在操作同一个变量时,底层表现为寄存器之间的操作,而操作寄存器的时候往往是多个寄存器操作,为防止存取不当,因此py脚本中的加法操作应该保证是顺序进行的。
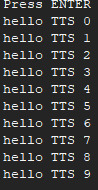
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
print('hello TTS', i)
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()
运行结果:
进程池(处理数据时最常用的)
Pool 类表示一个工作进程池。它具有允许以几种不同方式将任务分配到工作进程的方法。池的方法只能由创建它的进程使用。
from multiprocessing import Pool
import time
def f(x):
time.sleep(100)
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f,[1,2,3],))
运行结果:
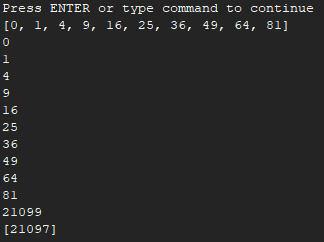
from multiprocessing import Pool, TimeoutError
import time
import os
def f(x):
return x*x
if __name__ == '__main__':
with Pool(processes=4) as pool:
print(pool.map(f, range(10)))
for i in pool.imap_unordered(f, range(10)):
print(i)
res = pool.apply_async(f, (20,))
print(res.get(timeout=1))
res = pool.apply_async(os.getpid, ())
print(res.get(timeout=1))
multiple_results = [pool.apply_async(os.getpid, ()) for i in range(4)]
print([res.get(timeout=1) for res in multiple_results])
res = pool.apply_async(time.sleep, (10,))
运行结果: