1 知识储备
1.1 html
html(HyperText Markup Language)是超文本标记语言,用于标记非文本信息,如图片,音频,表格或者我们需要的其他格式。
它存在的原因:图片视频等信息很难用文字去表达,因此我闷需要寻求表达超文本信息,以供浏览器内核解析。这便有了超文本标记语言。当然,除了html外,我们更常用的标记语言是markdown和tex。
html通过标签的形式来表达超文本信息,比如音频信息的标签是<audio>,那么我们想给网页添加音频的时候,把音频信息用<audio></audio>这组音频标签包围,中间放入音频的路径,
如:<audio controls>source src=“网址”</audio>。当浏览器解析到<audio>标签的时候,会读取路径并以音频的形式进行解码播放;当浏览器解析到</audio>标签,给浏览器的信息是音频标签结束了。
下面是一个例子:
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<title>这是一个测试网站</title>
</head>
<body>
<img align="center" src="img/tx.jpg" alt="头像" height="200" width="200" />
<h2 align="center">这是一篇文章:<a href="https://mp.weixin.qq.com/s?__biz=MzI2MjI3MzE4OA==&mid=2247483779&idx=1&sn=58b0034c1b5a86cd121e4ee7a8bf5612&exportkey=A66P5D%2B02gnm%2FcI5NcB2eGc%3D&pass_ticket=V3uRg6x%2Brkdqhkeuuv%2FQCF9YD4LtY%2FXWZif2Lj4I%2F9mDNxFItosV6aMLEv0DZEwE" align="middle">这是十九世纪的浪漫</a></h2></br>
<audio align= "center" src="music.m4a" preload="auto" style="width:1500px; " controls autoplay></audio> </br>
</body>
</html>
其中,html网页由head和body两部分组成,其中head是给浏览器的信息,body是呈现在我们的眼前的内容。搜索引擎通过对head中的title中的内容进行关键字检索并排序。
1.2 正则表达式
python的正则表达式包是re,我们可以通过import re使用它。它能对html脚本中的内容进行匹配,从而帮助我们准确的抓取我们需要的信息。
比如我们要抓取某网页上的jpg格式的图片链接,只需要对匹配.jpg便能完成任务。
这里我们需要简单了解下常用的正则表达式:
| 元字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符。 |
| [ ] | 字符类,匹配方括号中包含的任意字符。 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| ^ | 匹配行的开始 |
| $ | 匹配行的结束 |
| [a-z] | 匹配所有的小写字母 |
我们可以使用正则表达式匹配上面网页中的音频地址:findall是搜索string,以列表形式返回全部能匹配的子串。
re.findall(r'<audio src=.*\.m4a', string)
1.3 urllib
urllib是python的url处理模块,我们可以通过import urllib.request使用它。使用方法是
urllib.request.urlopen(url).read()
例如我们获取读取某个html网页的内容可以
url = "https://docs.python.org/zh-cn/3/library/urllib.html"
content = urllib.request.urlopen(url).read()
print(content)
2 实战抓取十一教师团队中的博士老师
2.1 在浏览器中进入十一官网的教师团队目录下,链接是十一名师。
2.2 用urllib读取网页信息
urllib.request.urlopen(url).read("http://www.bnds.cn/train/27.html")
2.3 按F12读取html并分析中的信息,如下图所示:
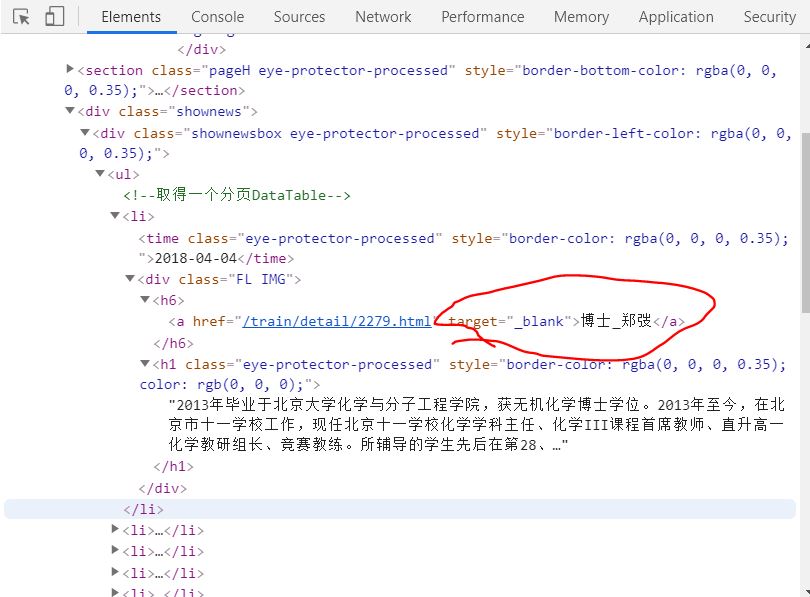 经过分析网页中的内容,可以通过下面代码匹配博士老师,匹配方式仁者见仁,智者见智哦。
经过分析网页中的内容,可以通过下面代码匹配博士老师,匹配方式仁者见仁,智者见智哦。
re.findall(r"博士_.+<\/a>", content.decode('utf-8')) # 以“博士”开头,“.” 匹配任意字符,“+” 表示匹配一个字或者多个字,“<\/a>”结尾
2.4 补全完整代码如下:
# coding=utf-8
import re
import urllib.request
url = "http://www.bnds.cn/train/27.html"
content = urllib.request.urlopen(url).read()
name_doctors = re.findall(r"博士_.+<\/a>", content.decode('utf-8'))
for name in name_doctors:
print(re.split(r"[_<]",name)[1])
其中re.split用于切割字符串,我们以”_“和”<”分割字符串,结果返回到列表中,其中第二个元素是老师姓名