GAN
PAPER:Generative Adversarial Nets
介绍
它是一种非监督学习,目标是训练生成器G使之生成数据无限接近于真实数据的分布。它实现了从低维到高维的映射。它的逼近方法是训练一个判别网络和生成网络相互博弈,论文中证明了解的存在性,正确性与唯一性。 理解:面对生成问题的时候,没有直接面对生成模型本身,而是通过可微的神经网络从采样的角度去逼近真实数据分布。
基本结构
we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. 理解:通过G和D的不断相互博弈,使G学习到真实的数据分布。
目标函数
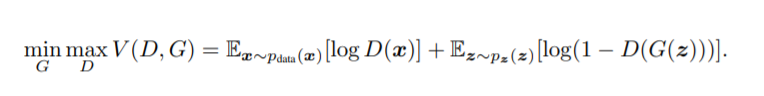
算法流程

缺点
1 GAN采用的是对抗训练的方式,G的梯度更新来自D,D的判断能力会影响G的最终学习效果。 2 词向量的离散性决定了GAN在应用在文本相关的生成模式中存在局限性。 3 G的生成结果不可控。
Conditional GANs
PAPER:Conditional Generative Adversarial Nets
问题:解决G的不可控性
实质:对G和D嵌入condition向量。
目标函数:
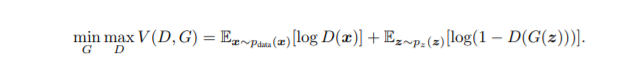 网络结构:
网络结构:
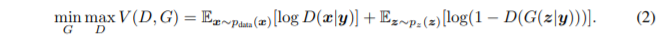
Controllable GAN
PAPER:Controllable Generative Adversarial Network
问题:GAN的generator不可控性
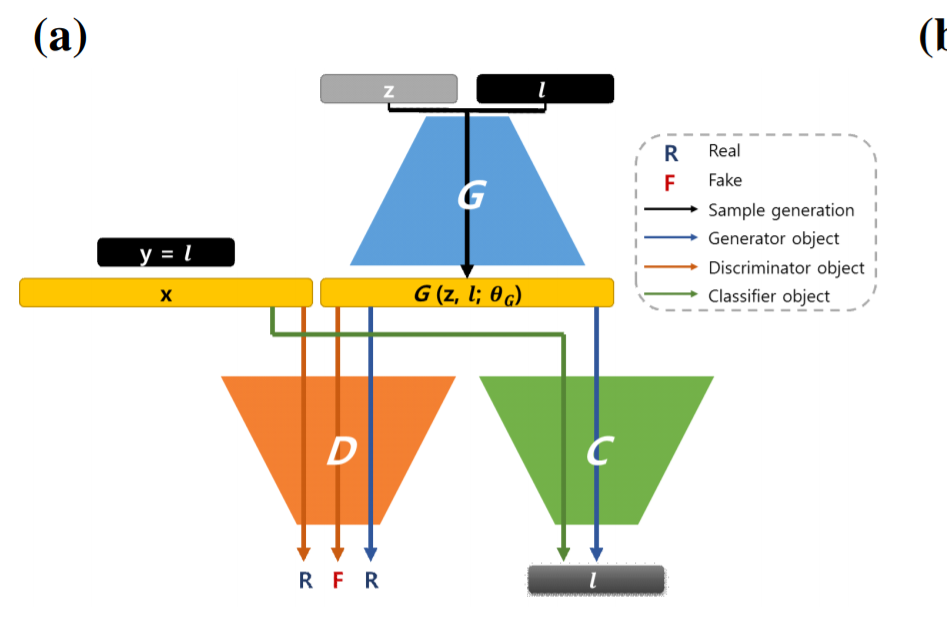
思路:给样本加入标签,同时zconcat上标签作为G的输入。另外添加分类器C,G的输出作为C的输入,输出为类别标签。
实质:嵌入类别标签。类似在tacotron中嵌入声纹信息以实现multi-speaker tts。
目标函数:
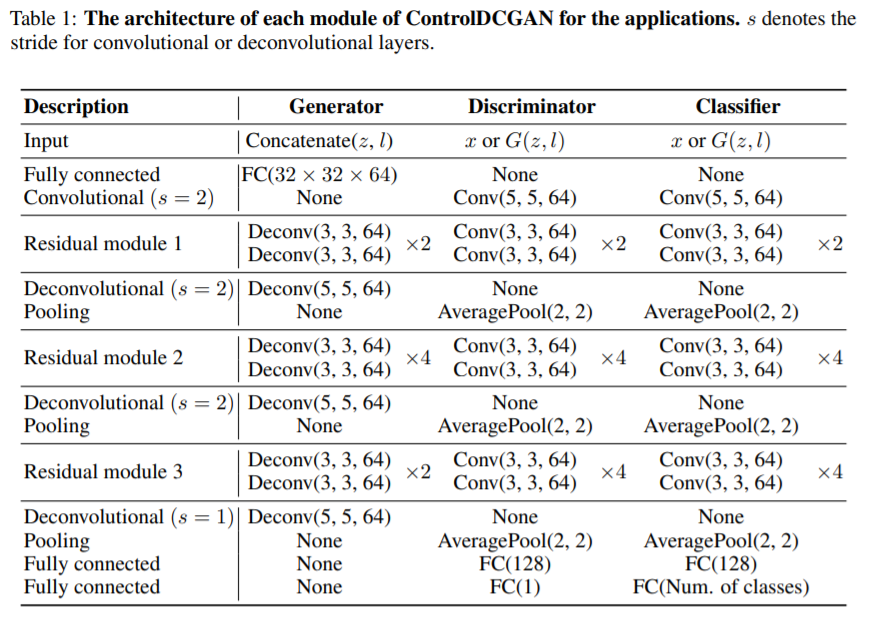
 网络结构:发生器由四个反卷积层组成。每层使用 5*5 的过滤器。 分类器由四个卷积层和 4 个反卷积层构成。分类器由 4 个卷积层和一个全连接层构成。
网络结构:发生器由四个反卷积层组成。每层使用 5*5 的过滤器。 分类器由四个卷积层和 4 个反卷积层构成。分类器由 4 个卷积层和一个全连接层构成。
DCGAN(deep convolutional generative adversarial networks )
PAPER:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
工作:第一次采用CNN实现了GAN模型,介绍了使用CNN的时候的技术细节。这篇论文对于WaveGAN的理解是非常重要的,WaveGAN作者根据DCGAN模型设计了WaveGAN。
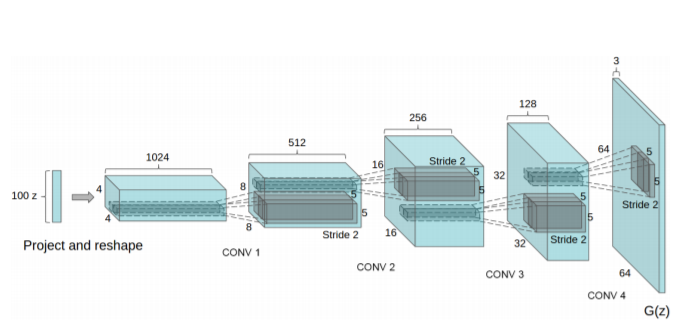
网络结构:输入的latent为长度为100,均匀分布的向量。上采样是通过转置卷积操作来进行。
 技术细节:在代码中都有所体现。
技术细节:在代码中都有所体现。


WaveGAN
PAPER:ADVERSARIAL AUDIO SYNTHESIS
简单介绍(video)
不同:DCGUN对二维的图像进行preject+N upsampling获得了很好的效果,音频和图像的不同在于:音频是一维的线性序列,短时平稳,数据量大,比如每秒16K个采样点,存储通常是16bit的整型,具有周期性和短时平稳性;图像是二维的,关注局部特征和边缘特性,分辨率低。
*思路:

 网络结构:和DCGAN相同。
网络结构:和DCGAN相同。

技术细节:在D的每一层convolution后采用Phase Shuffle。
specGAN:合成线性谱,再通过声码器合成音频。结果较WavGAN差。
合成结果:
wavegan_samples
MelGAN
PAPER:MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
问题:音频的采样率很高,直接对音频采样难度较高。对音频建模可以把音频转换成mel谱,合成时再把梅尔谱转换成音频。
理解:MelGAN是一种非自回归前馈神经网络(类似conditional GAN),G的输入是mel谱,输出是音频,因此实质上MelGAN是声码器。简单的网络结构能够实现高速合成。
网络结构:
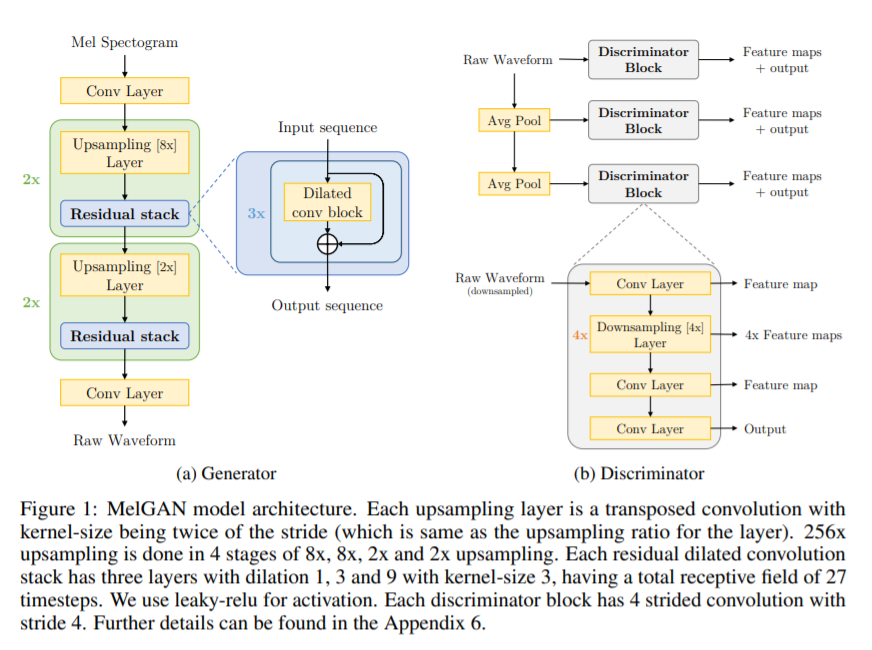 G的输入是Mel谱,经一层conv层后然后到经过两次8×后再经过两次2×,每次上采样后进行残差链接,残差结构中为dilated卷积(详细细节见论文)。之后经过一层conv层输出waveform。G使用了多尺度架构,也就是除了对waveform做判别,还对waveform进行两次average pooling,每次average pooling后都进行判别。D的设计是如图所示的下采样模块。
G的输入是Mel谱,经一层conv层后然后到经过两次8×后再经过两次2×,每次上采样后进行残差链接,残差结构中为dilated卷积(详细细节见论文)。之后经过一层conv层输出waveform。G使用了多尺度架构,也就是除了对waveform做判别,还对waveform进行两次average pooling,每次average pooling后都进行判别。D的设计是如图所示的下采样模块。
目标函数:采用了铰链损失函数
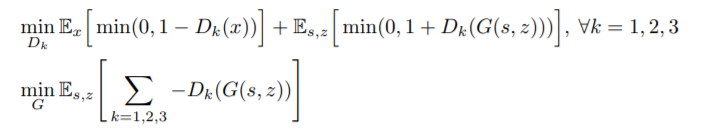
PARALLEL WAVEGAN
PAPER:PARALLEL WAVEGAN:A FAST WAVEFORM GENERATION MODEL BASED ONGENERATIVE ADVERSARIAL NETWORKS WITH MULTI-RESOLUTION SPECTROGRAM
github:ParallelWaveGAN
实质:以Conditional GAN为原型,以改进版的WaveNet做G,以mel谱做condition input的GAN的变种。
WaveNet改进:
 目标函数:
D的损失函数:
目标函数:
D的损失函数:
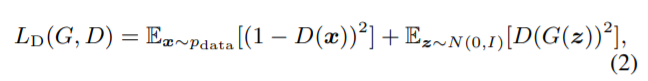 常规的G损失函数,但是除此之外,论文还设计了STFT损失函数(multi-resolution STFT auxiliary loss论文中指出为了提高GAN的稳定性和效率),定义最终的G损失由STFT损失和常规G损失组成。
常规的G损失函数,但是除此之外,论文还设计了STFT损失函数(multi-resolution STFT auxiliary loss论文中指出为了提高GAN的稳定性和效率),定义最终的G损失由STFT损失和常规G损失组成。
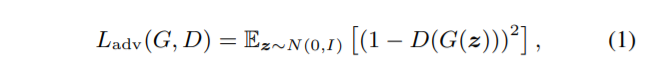
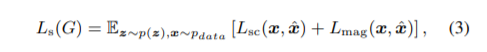

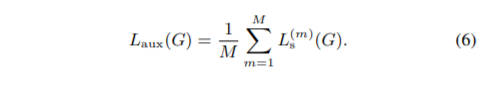 最终的G损失函数:
最终的G损失函数:
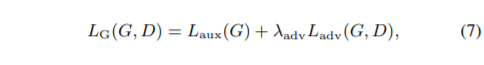 补充:F范数
补充:F范数
 音频合成:
PARALLEL WAVEGAN SAMPLES
音频合成:
PARALLEL WAVEGAN SAMPLES