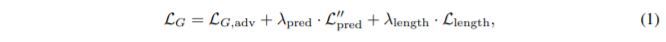介绍
论文提出了一种真正意义上的端到端TTS模型,通过前馈卷积神经网络和GAN实现了从文本或者音素直接生成波形。
整体的结构由两部分构成:Aligner和Decoder。Aligner由前向卷积神经网络,从原始的未对齐的音素或者文本生成对齐的200hz的隐层;Decoder是GAN-TTS,实现从200hz的隐层上采样到24khz的高质量音频。
虽然在log-mel spectrogram discriminator loss的计算使用频谱,但是只是为了提高模型的可训练性,并且在前向过程不使用频谱来生成wave。整个模型是end-to-end的,从文本到语音。
解决的问题
- 输出的高分辨率。每个音素或者文本所对应的输出往往是几k甚至十几K级别的,论文中使用的音频是24K hz。
- 对齐问题。TTS的任务是实现从文本或者音素到音频的映射,训练的输入为文本,输出为音频,而每个音素的时长以及无效音频长度是未知的。也就是说,我们不知道某个音素对应在音频上第几秒。
GAN-TTS简介
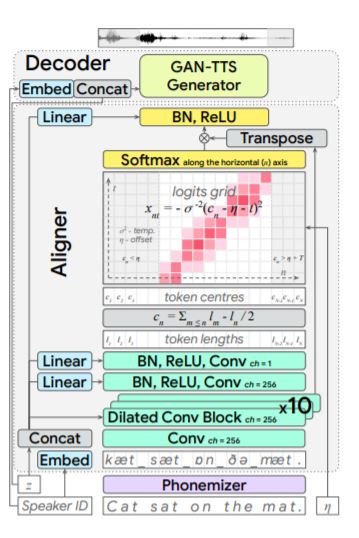
generator是由dilated前馈卷积神经网络组成,输入是单独的模型预测的语言学信息以及音高,时长等,输出为24khz的音频。discriminator集成多个判别器分别对音质和声音信息进行判别分析 , 其中五个不同窗长的conditional判别器使用语言学信息以及pitch作为condition对发音进行判别分析,五个不同窗长的unconditonal判别器对语音的听感或者是机械声进行判别分析。 模型整体上是可微的前馈卷积神经网络,摆脱了传统的声码器的自回归特性,因此可以GPU在实现并行推理,速度可观。
Alignner
Aligner由十组Dilated Conv Block组成,Dilated Conv Block由dilated conv1D以及ConditionalBatchNorm组成。Dilated Conv Block的输入为音素或文本,输出隐层用于预测每个归一化后的音素或文本对应的长度(时长), 用gaussian kernel 进行differentiable monotonic interpolation scheme,输出作为对齐的隐层。该隐层信息将作为Generator的输入。
Generator
EATS使用GAN-TTS generator作为生成器。输入为200hz的对齐后的隐层(Aligner的输出),输 出为24khz的音频。Generator由conv1D,7个GBlock,conv1D组成。GBlock见下图。
Discriminator
判别器由两部分组成:Random window discriminators和Spectrogram discriminator。
Random window discriminators
该部分由五个unconditional的不同分辨率的discriminator组成,窗长分别为240(10ms),480(20ms),960(40ms),1920(80ms),3600(150ms)。需要注意的是,该组判别器是unconditional的,它不包含输入的文本或者音素信息, 但是是以spkID和z作为condition。它不关心每个语音片段的语音片段蕴含的语言学信息是否相符,该组判别器判断真实值和预测值发音相似性(理解为声色是否相似),目标即为发出像”人“那样的声音,当然,此处的”人”是spk相关的。
Spectrogram discriminator
对训练的2s语音(以及real语音)提取log-mel spctrogram,同样也是以spkID作为condition。对整个片段的频谱,目标除了类似”人”的声音,增加了对应的语言学信息的对应。
Spectrogram prediction loss and dynamic time warping
在应用了上述的所有策略以及模型设计后,作者发现训练无法收敛。训练开始的时候,2s的语音片段完全不对应,会使GAN忽略aligner的输出,训练无法进行。因为discriminator是unconditional的,它
不知道输出的音频对应的文本或者音素。因此除了GAN的loss外,作者设计了下面的loss:
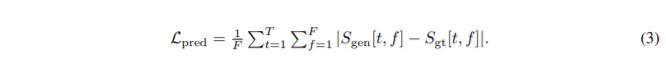 对整个训练语音片段2s进行计算所有通道的整个时间的log-mel spectrogram的L1范数的和(公式中除以通道数)。以此实现加速2ms片段的对齐。需要注意的是,这个loss和log-mel spectrogram discriminator loss是不同的。
同时作者提出了Dynamic time warping的策略改进了spectrogram prediction loss。
对整个训练语音片段2s进行计算所有通道的整个时间的log-mel spectrogram的L1范数的和(公式中除以通道数)。以此实现加速2ms片段的对齐。需要注意的是,这个loss和log-mel spectrogram discriminator loss是不同的。
同时作者提出了Dynamic time warping的策略改进了spectrogram prediction loss。
整体思路是:真实语音和预测语音理论上应该也是在时间轴上是对齐的。下面两种对齐路线中,完全对齐的路线是第一个。
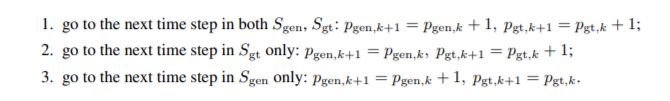 因此对第二种和第三种加以惩罚,走1路线时,w=0;走2或者3路线时,w=1.
因此对第二种和第三种加以惩罚,走1路线时,w=0;走2或者3路线时,w=1.
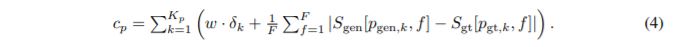
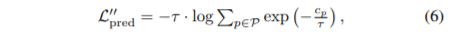
G loss设计
除了G loss以及spectrogram prediction loss,还添加了 aligner length loss:
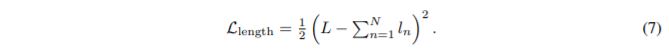 因此最终的G loss为:
因此最终的G loss为: